봄봄 SEO 개선기: 게재 순위가 폭락한 문제 해결하기
최근, 봄봄의 구글 검색 게재 순위가 불과 하루만에 폭락한 문제를 겪었습니다.
이번 글은 검색엔진 결과에서 서비스가 노출되지 않는 문제를 파악하고 해결한 과정을 소개하려 합니다.
봄봄은 Google Search Console에서 SEO 지표를 확인하며 관리하고 있습니다.
특히 저희 팀원들은 SEO를 중요하게 생각하며 최소 일주일에 두 번은 주기적으로 모니터링하고 있습니다.
마케팅 비용은 한정되어 있고, ‘뉴스레터’라는 도메인의 특성상 뉴스레터를 읽는 사람들이 ‘뉴스레터’를 검색하고 유입될 가능성이 큽니다.
따라서 저희는 검색 결과의 상위에 노출되는 것이 최소한의 비용으로 최고의 효율을 낼 수 있는 마케팅이라고 생각하고 있습니다.
배경
지난 2월 26일, 봄봄의 구글 검색 순위가 하루 만에 크게 떨어졌습니다.
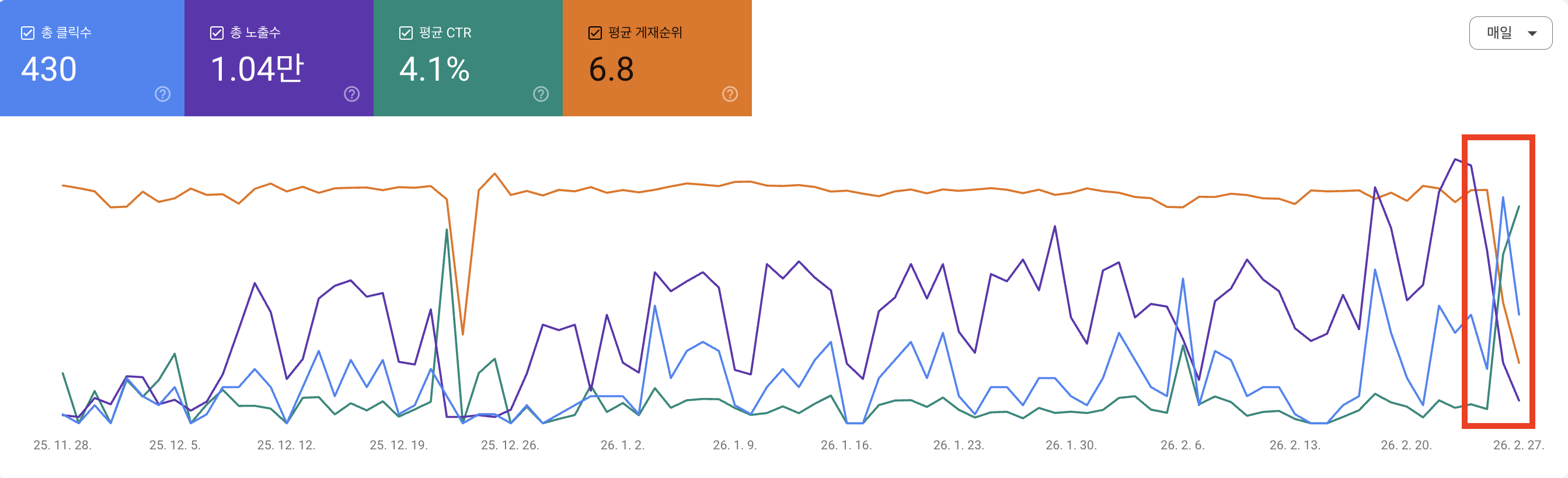
얼마 전까지만 해도 ‘봄봄’을 검색하면 무려 4위에 노출될 정도로 순위가 올라서 팀원 모두가 기뻐했습니다. (무려 김유정 봄봄과 카페 봄봄을 뚫고 올린 순위)
그러나 불과 며칠이 지나지 않아 1페이지를 한참 벗어나는 26위로 순위가 하락하여 충격이 더 컸습니다.
더욱 이상했던 건 별다른 조치를 하기 전인데도 검색 순위가 다시 4위로 회복됐다는 점이었습니다.
문제는 일단 해결된 것처럼 보였지만 원인을 정확히 파악하지 못한 채 넘어가면 같은 일이 다시 발생할 수 있다는 우려가 남았습니다.
다행히 순위가 회복되기 전에 Google Search Console로 해당 페이지를 점검해두었고, 문제 발생 시점의 테스트 결과도 따로 기록해둔 상태였습니다.
이에 원인을 추적하기 위해 기록을 다시 분석했고 그 과정에서 새로운 사실을 발견했습니다.
문제 분석
1. URL 테스트 실패
우선 Google Search Console에서 문제가 발생한 메인 페이지 URL(www.bombom.news)을 테스트해봤습니다.
Google Search Console에서는 특정 페이지가 검색엔진에 어떻게 수집되는지 확인할 수 있습니다.
그런데 결과를 확인해보니 noindex 태그 때문에 메인 페이지의 인덱싱이 차단된 상태였습니다.
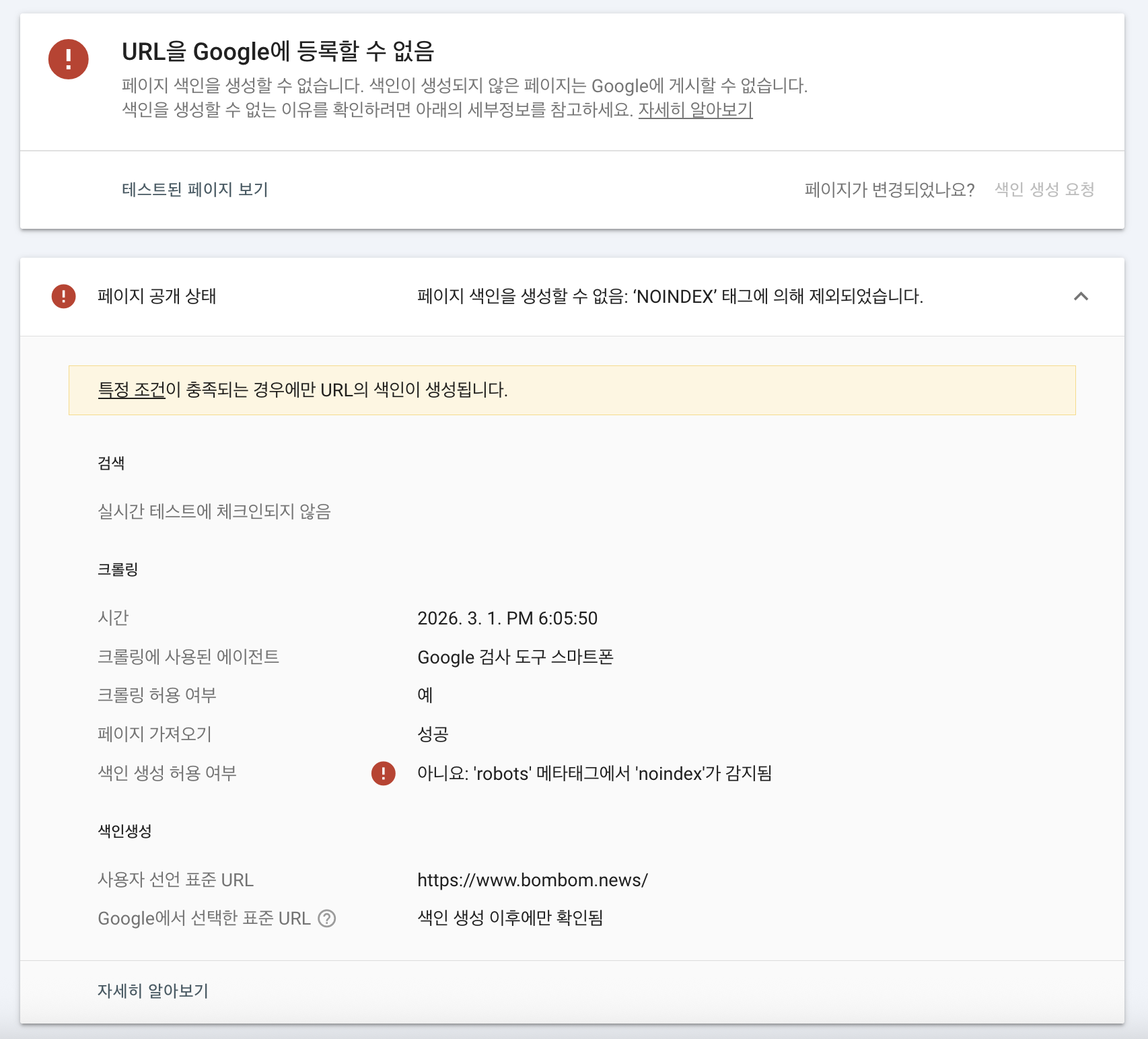
하지만 이 결과는 메인 페이지의 실제 인덱싱 설정과 모순됩니다.
메인 페이지(/)는 이미 index, follow로 설정해둔 상태였기 때문입니다. 그리고 이 설정은 페이지 생성 이후로 지금까지 바뀐 적이 없었습니다.
즉, 설정상으로는 분명히 인덱싱을 허용하고 있었는데 NOINDEX 결과를 얻은 것입니다.
2. noindex 태그의 출처
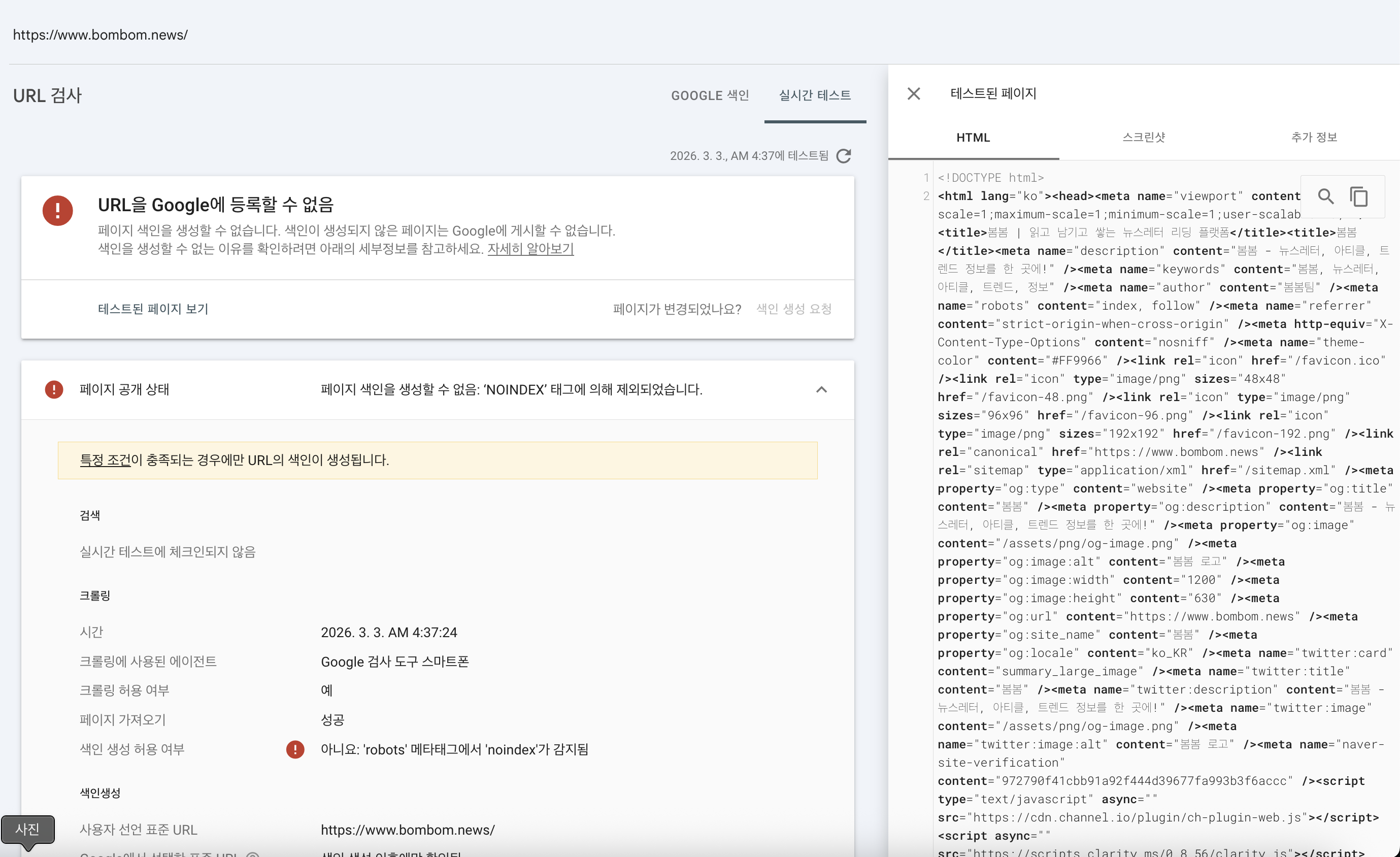
저는 이상하다고 느껴 실제로 크롤링된 HTML을 분석해봤습니다.
테스트된 HTML에서는 다음과 같은 특징을 확인할 수 있었습니다.
<head>상단에는/기준 메타 정보가 들어있음.<title>태그 2개: 각각/,/landing의 콘텐츠<body>에는/landing페이지가 렌더링된 결과가 들어있음.<head>안에는robots=index,follow와robots=noindex,follow가 함께 존재함.
특징을 종합해보면 HTML은 메인 페이지와 랜딩 페이지의 정보가 한 문서 안에 섞여 있는 듯한 구조였습니다. 여기에는 robots 태그도 포함되어 있었습니다.
이 정보를 토대로 noindex 문제가 랜딩 페이지의 robots 태그에서 발생한 점을 유추할 수 있었습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
<!doctype html>
<html lang="ko">
<head>
...
<meta name="robots" content="index, follow" />
...
<meta name="robots" content="noindex, follow" />
</head>
</html>
처음에는 서버가 HTML 파일 두 개를 잘못 이어붙여 응답한 것처럼 보였습니다.
하지만 테스트 대상 URL은 메인 페이지였기 때문에, 크롤링 봇이 왜 랜딩 페이지의 HTML까지 함께 수집했는지 의문이 남았습니다.
당시에 가장 가능성이 높다고 본 원인은 메인 페이지의 리다이렉트 로직이었습니다.
저희 서비스는 사용자의 방문 이력을 localStorage에 저장하고 첫 방문인 경우에는 랜딩 페이지로 이동시키는 구조로 되어 있었습니다.
이 구조를 기준으로 유추하면 크롤링 봇도 첫 방문 사용자처럼 메인 페이지에 진입한 뒤 랜딩 페이지로 이동했을 가능성이 높았습니다.
그리고 이 과정에서 메인 페이지와 랜딩 페이지의 정보가 함께 수집된 것으로 해석할 수 있었습니다.
여기까지 생각이 도달하니 크롤링 봇의 구체적인 크롤링 과정이 궁금해지기 시작했습니다.
크롤링 봇은 페이지에 접근하여 어느 시점의 데이터를 수집하는지, 그리고 지금처럼 여러 페이지의 데이터가 뒤섞인 결과는 왜 생기는지 호기심이 생겼습니다.
저는 Google에서 제공하는 SEO 공식 가이드를 참고하여 문제를 해석할 수 있는 자료를 찾았습니다.
의문 해결
왜 이런 HTML이 만들어졌을까?
저희 서비스의 메인페이지는 다음과 같은 동작을 수행하고 있습니다.
- 사용자가
/에 접속한다. - local storage의 데이터를 확인한다.
- 첫 방문 기록이 없으면
/landing으로 리다이렉트한다. - 첫 방문 기록이 있으면
/페이지를 보여준다.
- 첫 방문 기록이 없으면
이 리다이렉트 동작은 첫 방문 사용자에게 서비스를 소개하기 위해 넣어둔 기능이었습니다.
당시에는 크롤링 봇이 서버가 처음 내려준 HTML만 수집한다고 생각했고 이 동작이 검색 결과에 영향을 줄 것이라고 예상하지 못했습니다.
하지만 실제 봇의 동작은 생각했던 것과 달랐습니다.
Google Search Central 문서에 따르면, Googlebot은 JavaScript 페이지를 대략 다음과 같은 흐름으로 처리합니다.
- URL 크롤링
- HTML 파싱 및 링크 발견
- 렌더링 큐 등록
- JavaScript 실행
- 렌더링 된 HTML 재분석
- 인덱싱 및 canonical 판단
Google은 크롤링, 렌더링, 인덱싱 세 가지 주요 단계로 자바스크립트 웹 앱의 데이터를 수집합니다.
먼저 Googlebot이 URL을 발견하면 초기 HTML을 크롤링 합니다.
그리고 HTML을 렌더링하여 추가 리소스에 대한 크롤링 정책을 robots.txt로 확인합니다.
robots.txt를 토대로 허용된 리소스를 가져오면 JavaScript 리다이렉트 여부를 확인하여 필요하다면 다시 새로운 페이지를 렌더링합니다.
이후 최종 렌더링된 콘텐츠를 인덱싱하여 검색엔진에 업데이트합니다.
즉, 크롤러는 단순히 서버가 처음 내려준 HTML만 읽고 끝나는 것이 아니었니다.
초기 HTML 이후에도, JavaScript 실행 후 라우팅 결과까지 다시 반영해 판단할 수 있습니다.
앞서 언급한 바와 같이 저희 서비스의 메인 페이지에는 리다이렉트 로직이 존재합니다. 따라서 일부 경우에는 초기 HTML이 유지되지 않습니다.
결과적으로 서버는 /에 대한 초기 HTML을 내려주지만 브라우저가 JavaScript를 실행한 이후에는 /landing 기준의 화면과 메타 정보가 반영될 수 있는 구조였습니다.
지금까지 알게된 내용을 봄봄에 대입해보면 봇은 아래와 같은 흐름으로 페이지를 크롤링합니다.
/요청이 들어오면 서버는 기본 index.html을 반환한다.- 기본
<head>정보를 포함
1 2 3
<title>봄봄</title> robots=index, follow
- 기본
이후 JavaScript가 실행되면서 Router가 동작한다.
- 앱이
/landing라우트를 렌더링하면<body>는 랜딩 페이지 콘텐츠로 바뀌고<head>에도 랜딩 페이지용 메타 태그가 추가된다.- 기본
<head>+ 랜딩<head>
1 2 3 4 5 6 7
<title>봄봄</title> <title>봄봄 | 읽고 남기고 쌓는 뉴스레터 리딩 플랫폼</title> robots=index, follow robots=noindex, follow - 기본
현재, 각 페이지는 Tanstack Router의 HeadContent를 사용하여 Route 기준으로 <head>에 넣을 태그들을 렌더링하고 있습니다.
그러나 공교롭게도, HeadContent는 Router가 만든 중복 태그는 제거해주지만, 기존의 정적 index.html에 있던 태그와의 중복은 고려해주지 않습니다.
결국 만들어진 HTML 결과에는 정적 파일의 태그와 랜딩 페이지의 태그가 공존하게 됩니다.
검색엔진 입장에서는 처음에는 /의 <head>를 읽고, 이후 JavaScript 실행 결과로 /landing의 <body>와 추가된 <head> 정보를 보게 된 셈입니다.
그래서 최종적으로는 두 HTML 파일이 합쳐진 것처럼 보이는 문서가 수집됩니다.
하지만 실제로는 파일을 합친게 아니라, 하나의 SPA 문서가 JavaScript가 실행되면서 변경된 결과에 가깝습니다.
왜 어떤 시점에는 정상이고, 어떤 시점에는 문제가 생길까?
이 문제가 더 아리송했던 이유는 같은 구조를 유지해도 검색 결과가 항상 똑같이 나타나지 않았기 때문입니다.
크롤링 정책과 관련된 코드를 수정하지 않았는데도 갑작스럽게 순위가 폭락했고, 특별한 조치 없이도 저절로 회복되었습니다.
이는 Googlebot이 메인 페이지와 랜딩 페이지에 다양한 경로로 접근할 수 있었고, 그 과정에서 노출되는 문서 상태와 SEO 정보가 서로 일관되지 않았기 때문이었습니다.
당시 서비스의 SEO 정책은 다음과 같았습니다.
- 검색 결과에 대표로 노출시키고자 한 URL은
/이었습니다. - 크롤러의 제한된 렌더링 자원을 고려해, 봇이
/에 접근하면 일반 SPA 초기 HTML 대신 미리 렌더링한 정적 HTML을 응답하도록 구성했습니다. (prerendered) - SEO 정책상
/landing은 검색 노출 대상에서 제외하기로 했고, 이에 따라 noindex를 설정했습니다. - 그러나 sitemap에는 여전히
/landing이 포함되어 있었습니다.
랜딩페이지에 noindex를 설정했지만 sitemap에 추가하는 등 일관되지 않은 SEO 정책은 Google의 검색엔진 동작과 맞물려 불안정한 인덱싱을 유발했습니다.
1. Google은 JavaScript 페이지를 단계적으로 처리한다.
앞서 설명드린 내용처럼 Googlebot은 먼저 HTML을 크롤링한 뒤, 이후 렌더링 단계에서 JavaScript를 실행하고 결과물인 HTML을 다시 분석합니다.
이 사실 자체가 검색 결과의 변동을 직접 설명해주지는 않습니다. 다만 현재처럼 /에 대해 서로 다른 응답 경로가 존재하는 구조에서는
JavaScript 실행 이후의 상태 역시 검색엔진 해석에 포함될 수 있다는 점을 의미합니다.
즉, /에 대한 서버 응답만 보는 것으로 끝나는 것이 아니라, JavaScript 실행 이후의 상태도 검색엔진 처리 과정에 포함될 수 있습니다.
우리 서비스에서는 어떤 요청은 봇 분기를 통해 정적 HTML을 받았고, 어떤 요청은 일반 / 페이지를 받은 뒤 JavaScript 실행을 통해 /landing 상태까지 도달할 수 있었습니다.
따라서 동일한 / URL이라도 검색엔진이 항상 동일한 상태의 문서만 보는 구조가 아니었습니다.
2. 대표 URL 관련 신호(signal)와 인덱싱 정책이 서로 일관되지 않았다.
Google Search Central 문서는 canonical URL을 선택할 때 rel="canonical", redirect, sitemap inclusion 등 여러 신호를 함께 참고한다고 설명합니다.
이 신호들은 중요도와 우선순위가 서로 다르고, 일관되게 설정해둘수록 Google이 서비스의 의도대로 대표 URL을 선택할 가능성이 높아집니다.
그러나 당시 서비스 구조에서는 /를 대표 URL로 노출하고자 하였음에도 /landing를 sitemap에 포함하면서 noindex로 두는 모순된 설정이 있었습니다.
또한 /로 진입한 뒤 JavaScript가 실행되면 /landing의 콘텐츠와 메타 정보가 함께 나타날 수 있었습니다.
결국 검색 엔진이 페이지를 해석할 때 참고하는 정보들이 처음부터 일관되게 정리되어 있지 않았던 것입니다.
정리: 문제의 핵심 원인
결론적으로 이번 문제의 핵심은 아래 세 가지였습니다.
1. 혼합된 HTML이 만들어지는 구조였다.
/의 초기 HTML은 완성된 페이지가 아니라 JavaScript 실행 전의 기본 문서였다.- JavaScript가 실행되면 앱은
/landing으로 이동할 수 있었다. - TanStack Router의
HeadContent는 정적index.html의 head 태그를 교체하지 않고, 라우팅된 페이지의 메타 태그를 추가로 렌더링했다.
그 결과 하나의 문서 안에 /의 초기 메타 정보와 /landing의 렌더링 결과가 공존하게 되었습니다.
이로 인해 noindex 문제가 발생했습니다.
2. 대표 URL 관련 정보와 인덱싱 정책이 서로 일관되지 않았다.
- 검색 결과에 대표로 노출시키고 싶은 URL은
/이었다. - 그러나
/landing은 sitemap에 포함되어 있었다. - 동시에
/landing에는noindex가 설정되어 있었다. - 반면 JavaScript 실행 이후에는
/landing의 콘텐츠와 메타 정보가 실제 문서에 나타날 수 있었다.
즉 검색엔진 입장에서는 대표로 이해해야 할 URL, 실제 렌더링 결과, 인덱싱 정책이 한 방향으로 정리되어 있지 않았습니다.
이 불일치가 예상과 다른 인덱싱 결과와 변동성을 만들었습니다.
최종 결론
이번 문제는 서버가 HTML 파일 두 개를 잘못 합쳐서 내려준 문제가 아니었습니다.
실제로는,
/요청 시 반환된 초기 SPA HTML- JavaScript 실행 이후 반영된
/landing라우트의 렌더링 결과
이 두 단계가 검색엔진의 분석 과정에서 함께 반영되면서,
결과적으로 <head>와 <body>가 섞인 것처럼 보이는 HTML이 관찰된 것입니다.
그리고 이 과정에서 robots=index와 robots=noindex가 동시에 노출되었고, 검색엔진이 페이지의 대표성과 인덱싱 가능 여부를 일관되게 해석하기 어려운 상태가 만들어졌습니다.
배운 점
SPA 환경에서 SEO를 다룰 때는 단순히 초기 HTML에 메타 태그를 넣은 것 만으로 충분하지 않습니다.
실제로는 아래 조건들이 모두 일관되어야 합니다.
- 서버가 반환하는 초기 HTML
- JavaScript 실행 후 최종 렌더링 결과
- Route별 메타 태그 주입 방식
- canonical 설정
- sitemap에 포함된 URL
- robots 정책
특히 초기 URL과 최종 렌더링 URL이 다르고, 그 과정에서 <head> 정보까지 동적으로 바뀌는 구조라면
검색엔진은 우리가 예상한 것과 전혀 다른 형태로 페이지를 해석할 수 있습니다.
이번 이슈는 단순한 noindex 실수가 아니라,
SPA 렌더링 구조와 검색엔진 처리 방식이 충돌하면서 생긴 문제라는 점을 알게 되었습니다.
참고 자료
[Google JavaScript SEO basics]
https://developers.google.com/search/docs/crawling-indexing/javascript/javascript-seo-basics
[Google redirects]
https://developers.google.com/search/docs/crawling-indexing/301-redirects
[Google canonical guidelines]
https://developers.google.com/search/docs/crawling-indexing/consolidate-duplicate-urls
[Google sitemap guidelines]
https://developers.google.com/search/docs/crawling-indexing/sitemaps/build-sitemap
[Google WRS state behavior]
https://developers.google.com/search/docs/crawling-indexing/javascript/fix-search-javascript
[Google dynamic rendering guidance]
https://developers.google.com/search/docs/crawling-indexing/javascript/dynamic-rendering
[How Google handles JavaScript throughout the indexing process]
https://vercel.com/blog/how-google-handles-javascript-throughout-the-indexing-process